A Comprehensive Mechanistic Interpretability Explainer & Glossary
Interpreting GPT: the logit lens - Also see the “Mentioned in” section at the end.

A jargon-free explanation of how AI large language models work
 - including the brilliant squirrels analogy for how NNs are trained.
- including the brilliant squirrels analogy for how NNs are trained.
You can think of the attention mechanism as a matchmaking service for words.
You can think of all those [12288] dimensions as a kind of “scratch space” that GPT-3 can use to write notes to itself about the context of each word. Notes made by earlier layers can be read and modified by later layers, allowing the model to gradually sharpen its understanding of the passage as a whole.
There’s also this quip:
A kind of “clever Hans” effect, only in language models rather than horses.
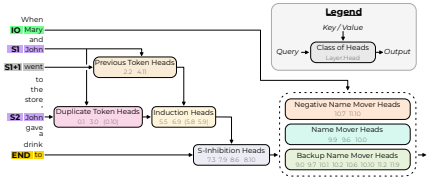
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Transformer Feed-Forward Layers Are Key-Value Memories
A Mechanism for Solving Relational Tasks in Transformer Language Models - e.g., capital_of(Poland)=Warsaw
A Mathematical Framework for Transformer Circuits - Anthropic
In-context Learning and Induction Heads - Anthropic
GPT-3 has “learned how to learn”: in its endless training on so many gigabytes of text, it encounters so many different kinds of text that it had no choice but to learn abstractions.
This family of phenomena is perhaps driven by neural networks functioning as ensembles of many sub-networks.
It is sufficiently powerful a model that its sub-models can do anything from poetry to arithmetic, and it is trained on so much data that those superficial models may do well early on, but gradually fall behind more abstract models.
Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
Softmax Linear Units - Anthropic - Making models more interpretable
-
Many MLP neurons appear to be polysemantic, responding to multiple unrelated features (unlike the Grandmother cell).
-
One plausible explanation for polysemanticity is the superposition hypothesis, which suggests that neural network layers have more features than neurons as part of a “sparse coding” strategy to simulate a much larger layer.
Other
-
The nodes are the variables and the weights are the program.
-
Causal interventions on the internals of a model.
- Activation patching - run the model twice; replace a node’s activation in one run with the activation from the other run.
-
It measures counter-factuals. What would
-
Path patching
-
Automatic circuit discovery
-
With patching in general, you have to choose your input distribution carefully.
- Attention heads (?) can refer to other info by value or by pointer. They showed that, in their IOI example, the second John was being referred to by (relative) pointer.